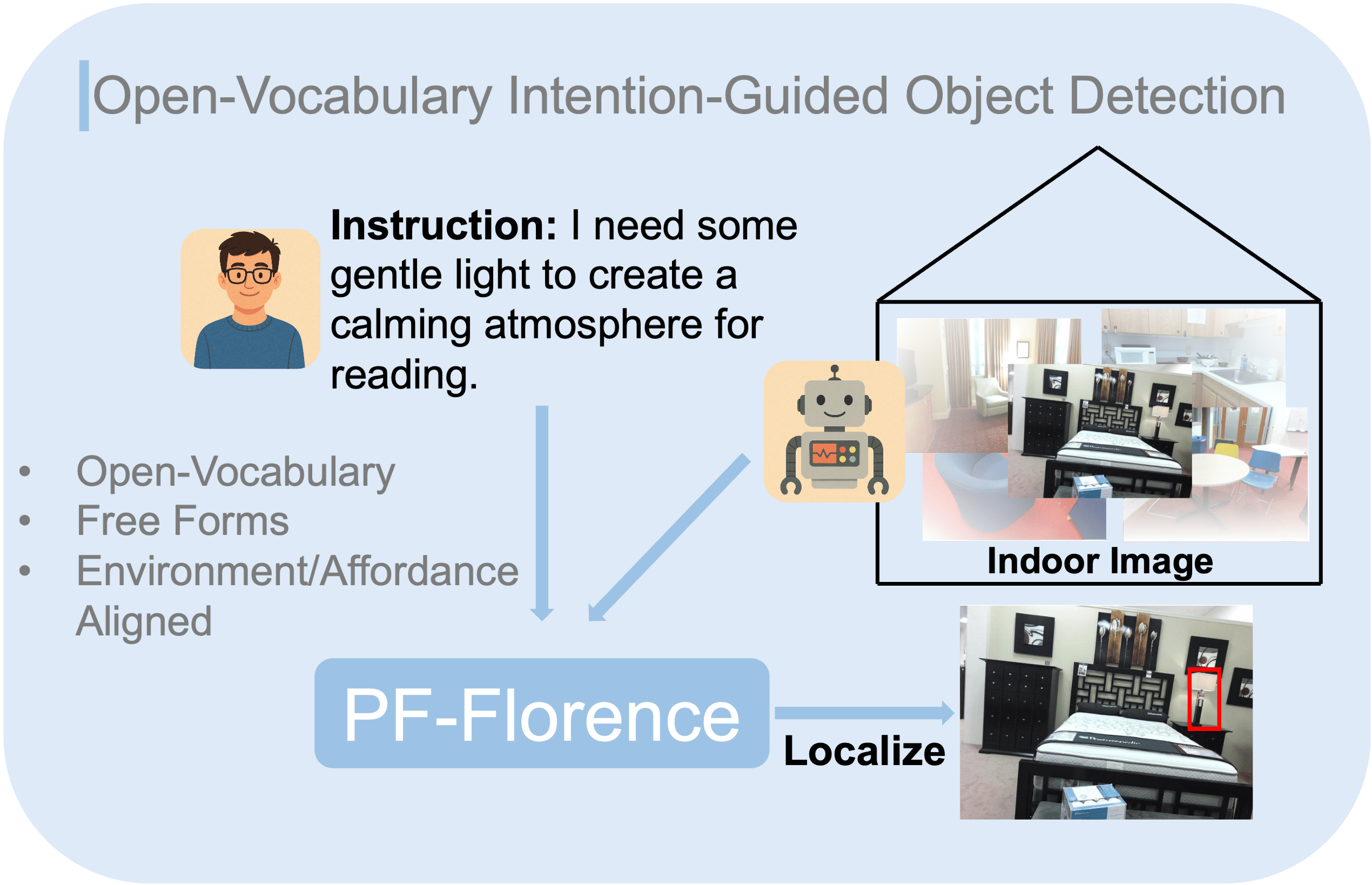
Understanding and responding to human intentions in visual environments is a crucial capability for embodied agents to provide intuitive assistance. We introduce Open-Vocabulary Intention-Guided Object Detection (OV-IGOD), a novel task requiring detection of objects that fulfill free-form human intentions. This task presents unique challenges beyond traditional object detection or visual grounding, as it demands understanding implicit needs, reasoning about object affordances, and precise localizing relevant targets.
To advance research in this direction, we introduce OV-IGOD Bench, a novel benchmark featuring 9.3k images and 21.5k diverse intention annotations that preserve contextual relevance, spatial precision, and natural language variation. Our data construction pipeline employs a multi-stage approach combining detail caption generation by InternVL3-8B, intention prompting with GPT-4o, and quality review.
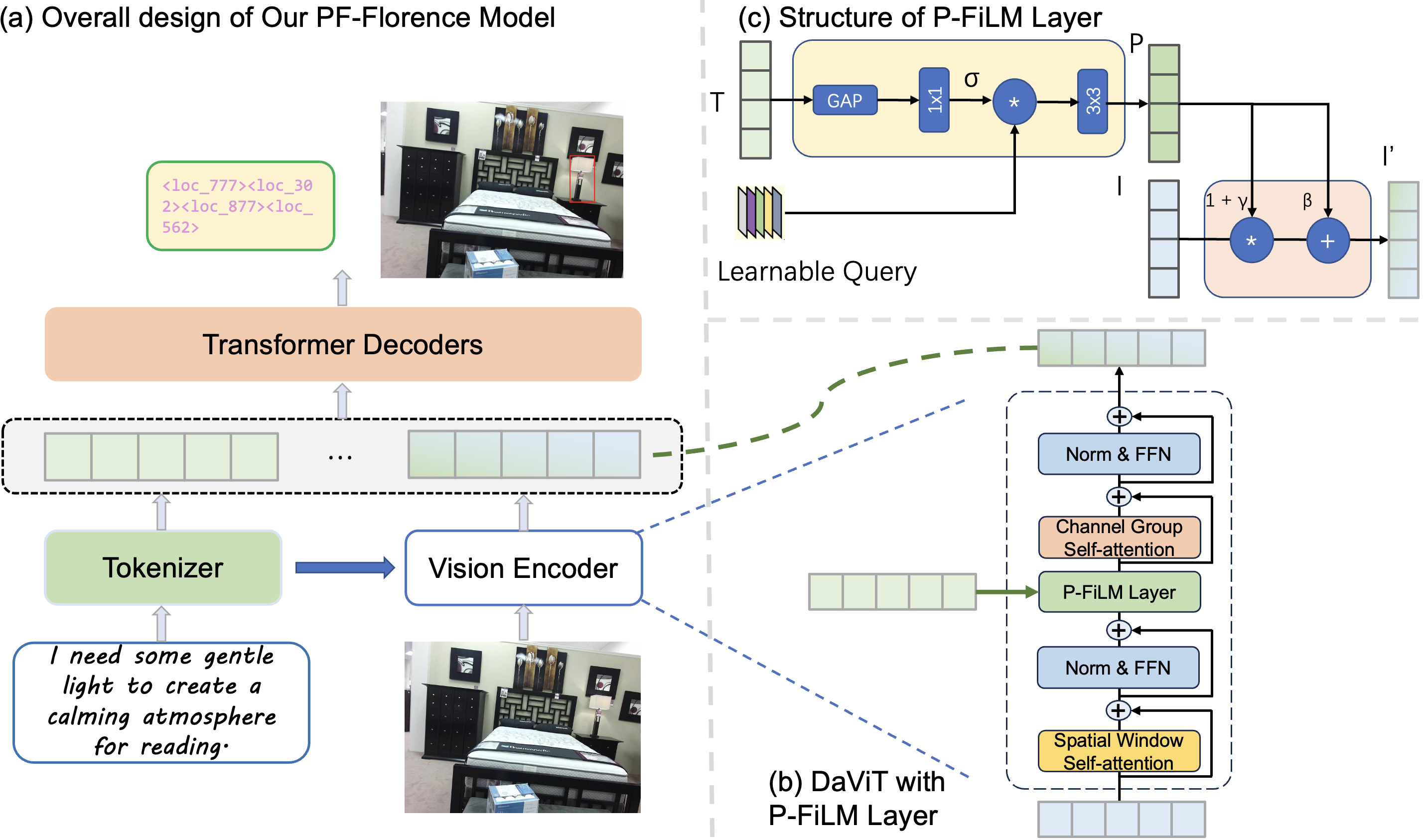
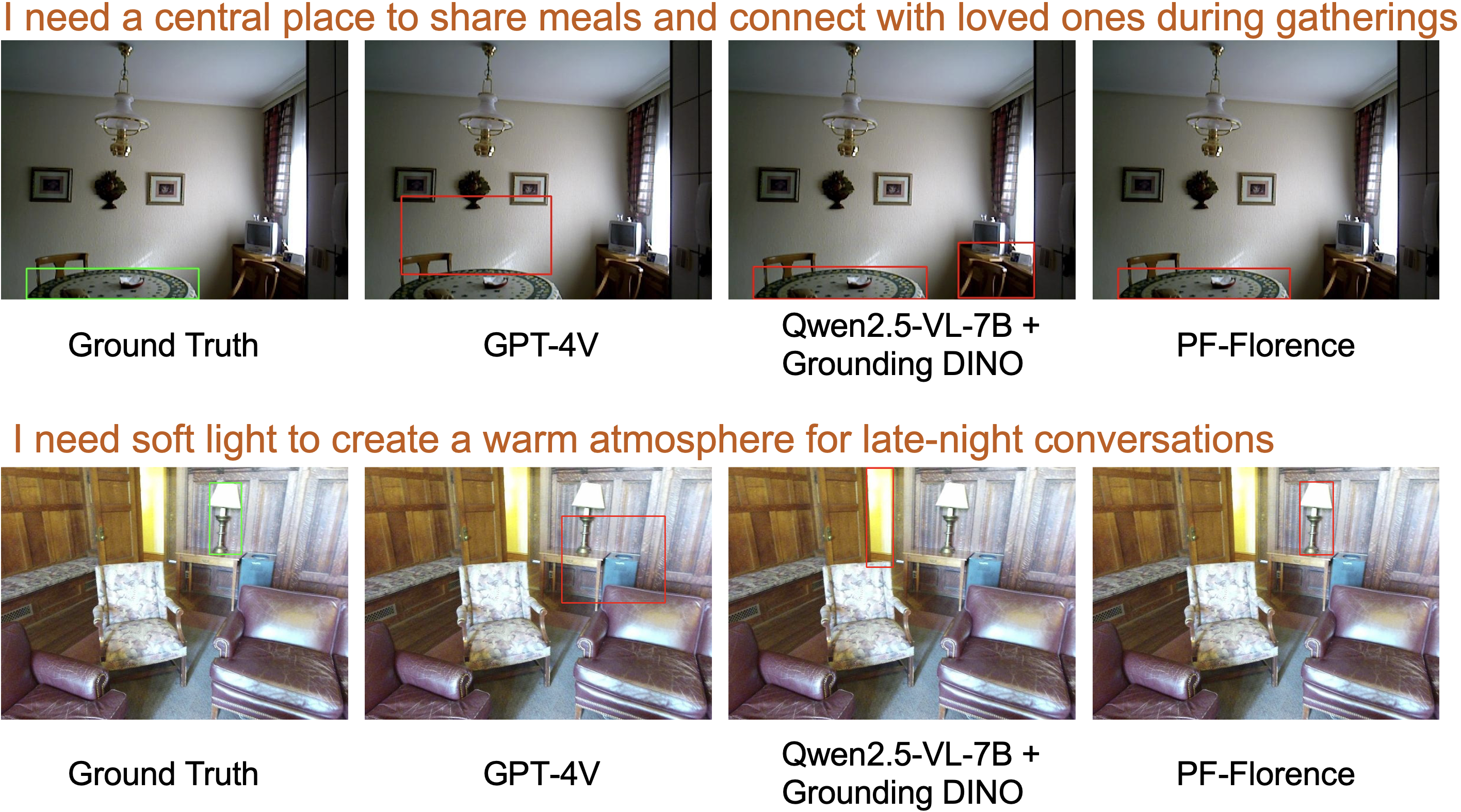
Leveraging this benchmark, we develop PF-Florence, which enhances the Florence-2 vision-language model with our proposed Prompted Feature-wise Linear Modulation (P-FiLM) mechanism. P-FiLM addresses limitations in conventional modulation approaches by incorporating learnable queries that selectively extract and utilize textual information for visual feature conditioning. Our method significantly outperforms existing approaches on standard object detection metrics. Real-world experiments further validate the practical applicability of our approach in zero-shot transfer settings.